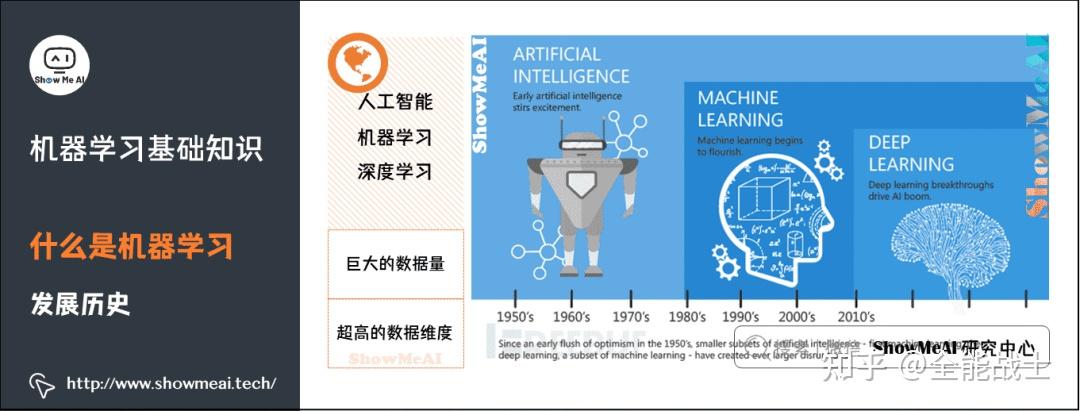
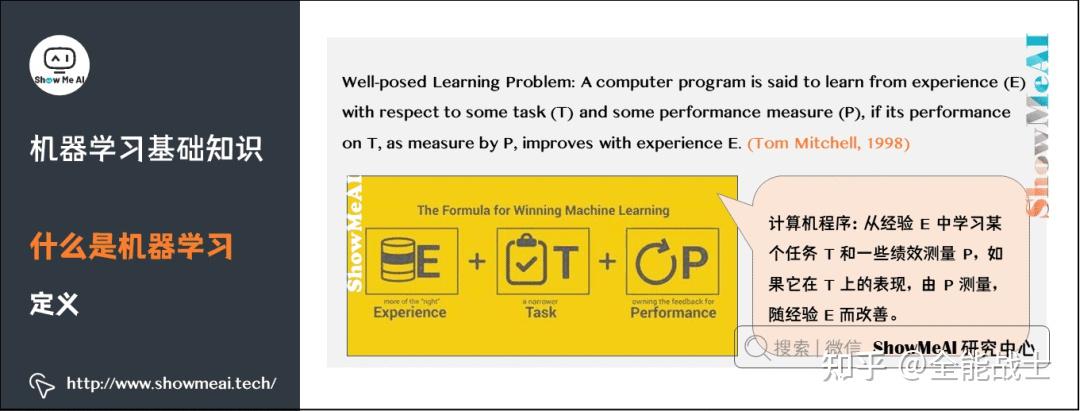
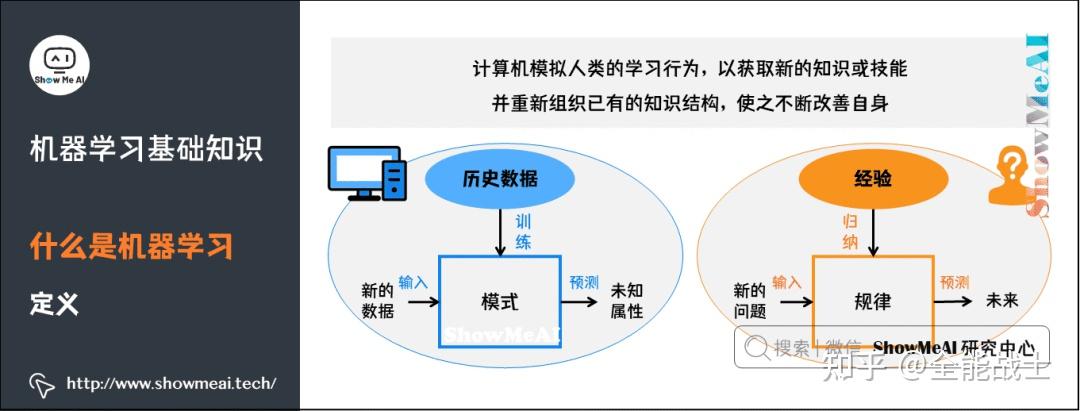
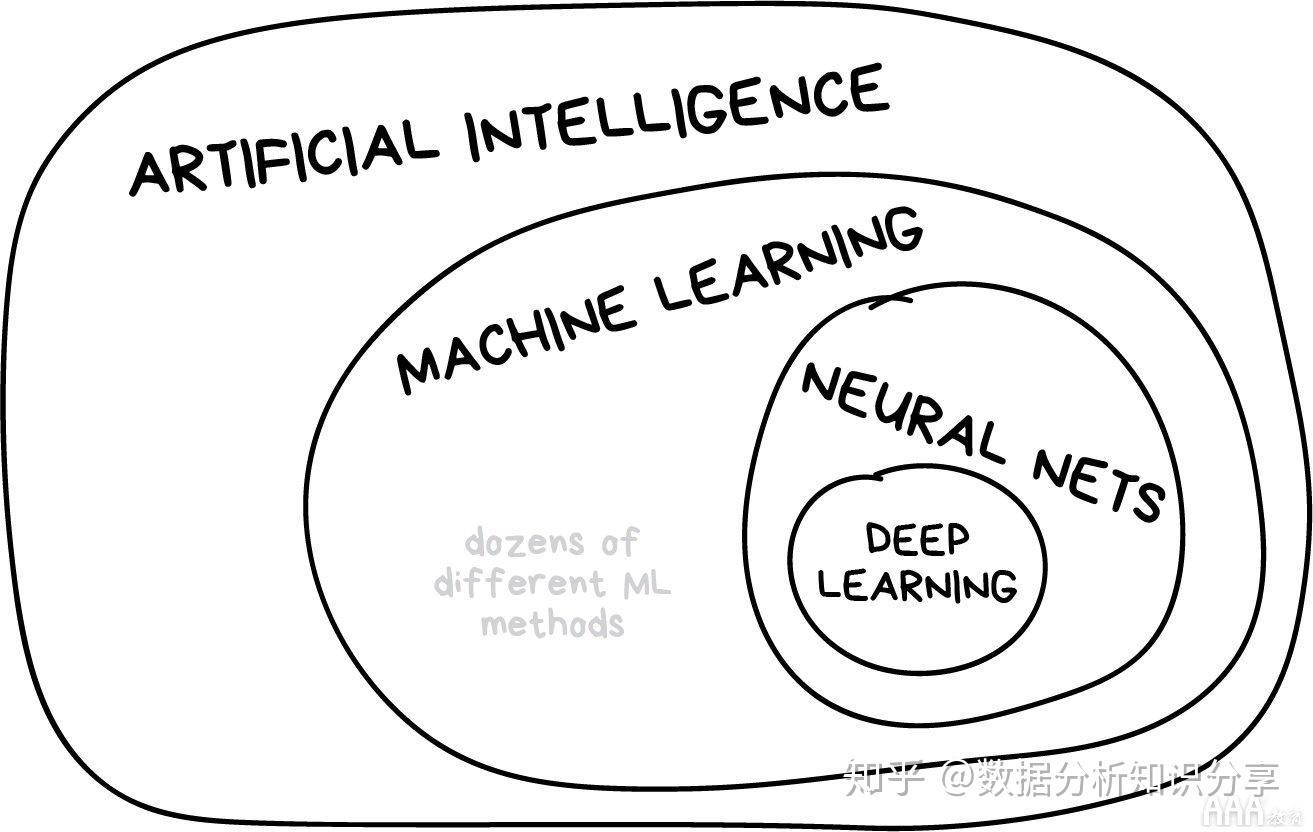
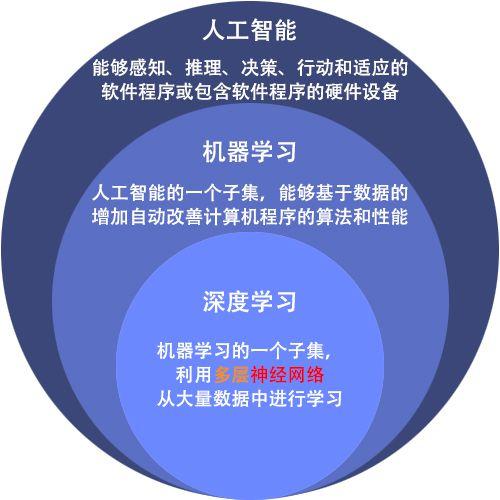
机器学习 (ML) 是人工智能的一个子集,是一个快速发展的领域,越来越多的制药公司利用它。将ML方法集成到药物开发过程中,帮助自动化重复的数据处理和分析任务。
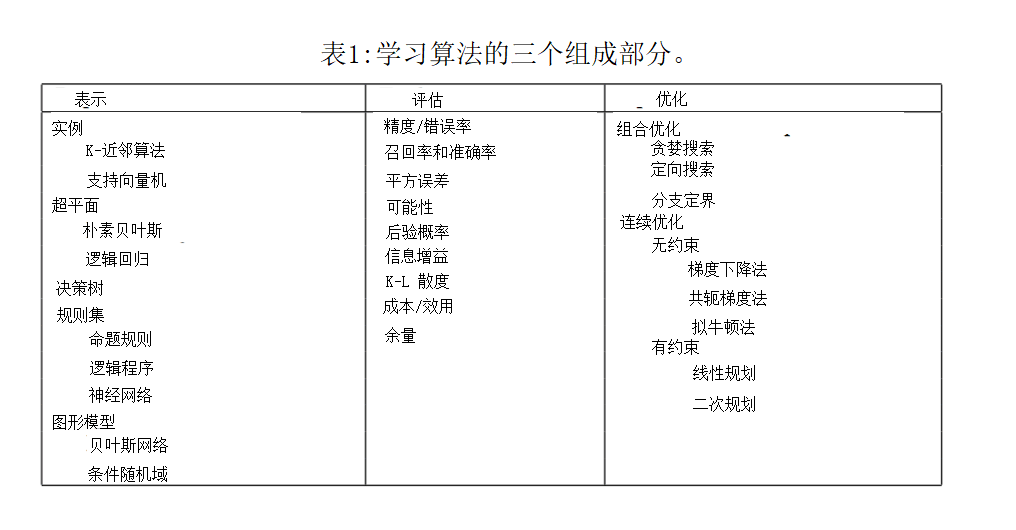
机器学习——做出数据驱动的决策
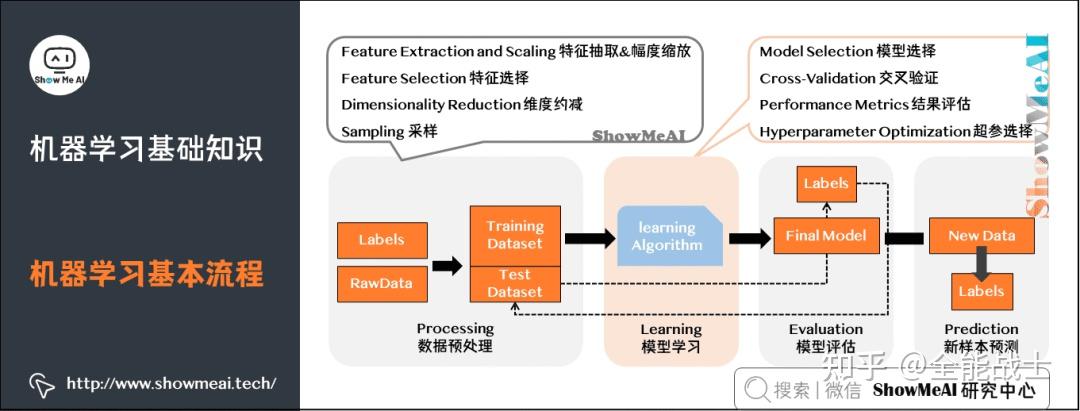
ML 解决方案基于大数据建模和分析。数据可以来自不同来源(例如,数据存储库、内部实验和出版物)并且可以在格式有所不同,这使得数据的聚合、存储和准备具有挑战性。
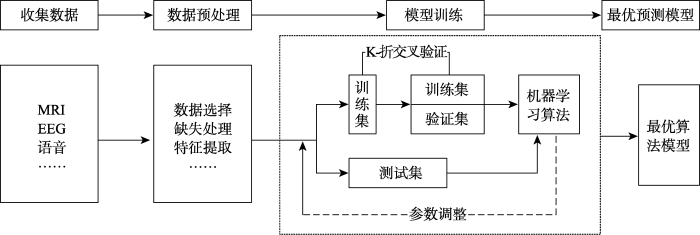
图一基于ML建立抑郁症预测模型的思路框架
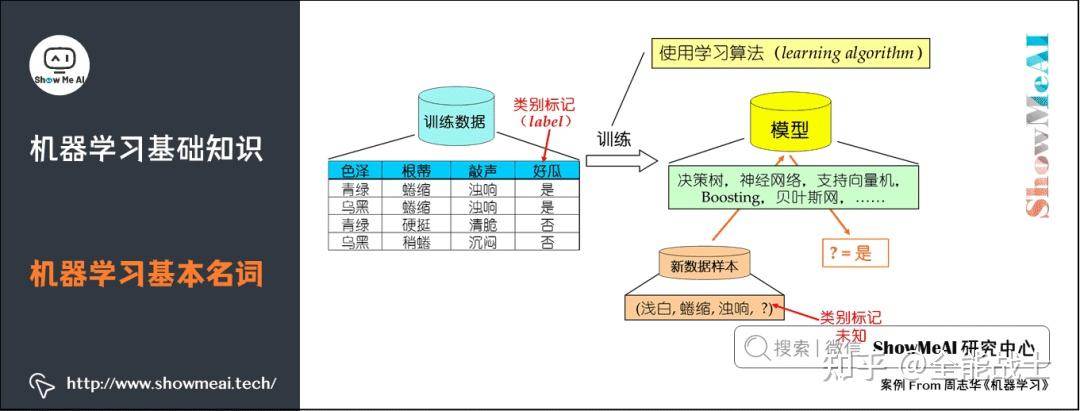
ML 训练系统在没有任何外部支持的情况下,自主地做出推理和决策。当系统从过去的经验中学习和改进时,就会做出决定——系统从所提供的数据中学习,并解读其中包含的相关模式。然后,通过模式识别和分析,系统交付“结果”,这可能是一个预测或分类。
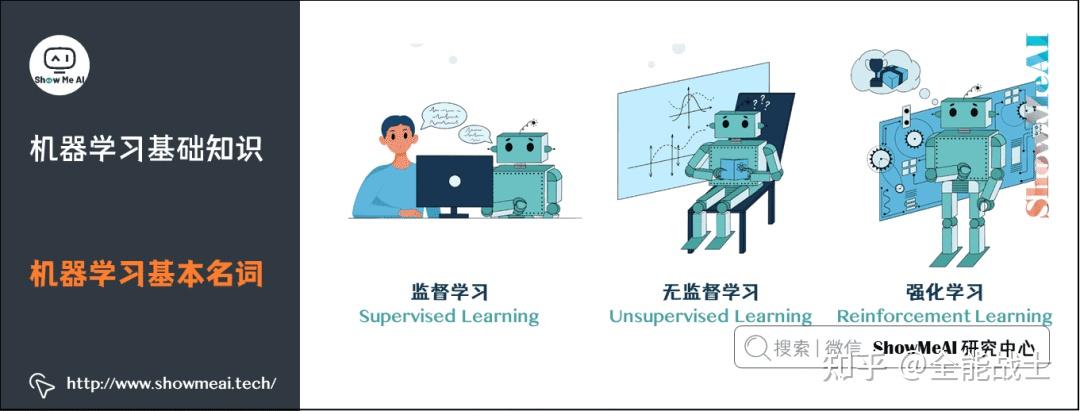
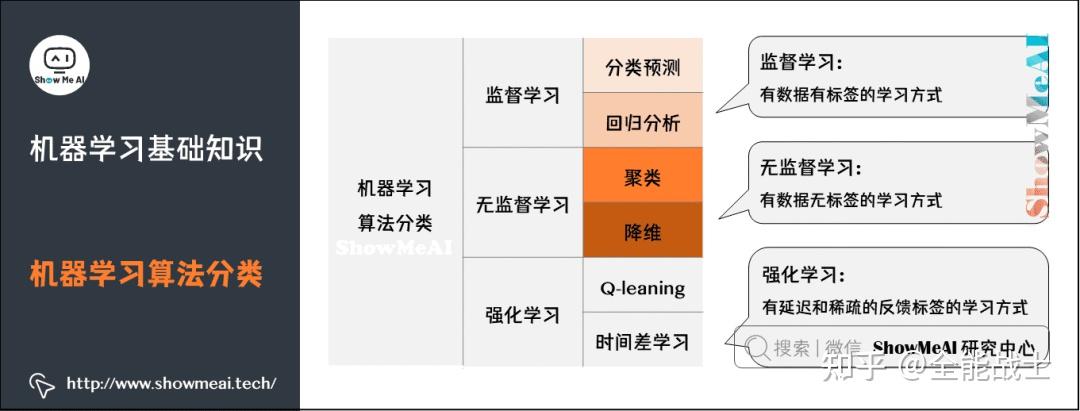
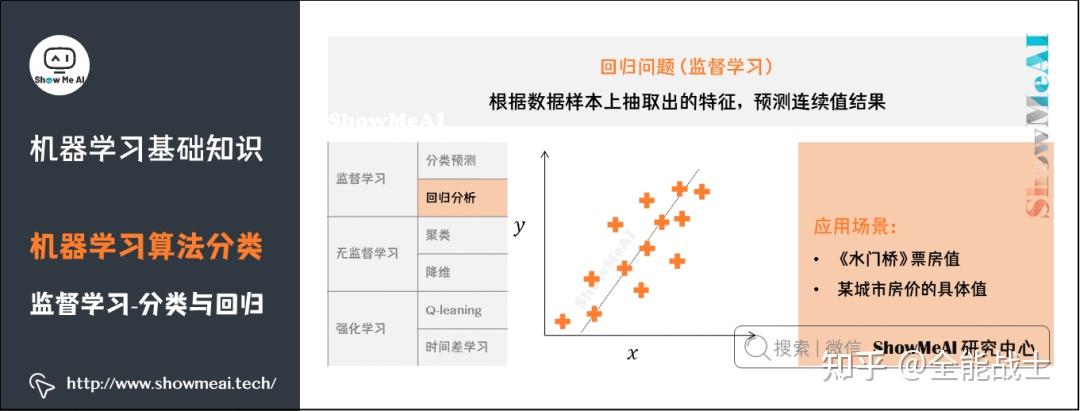
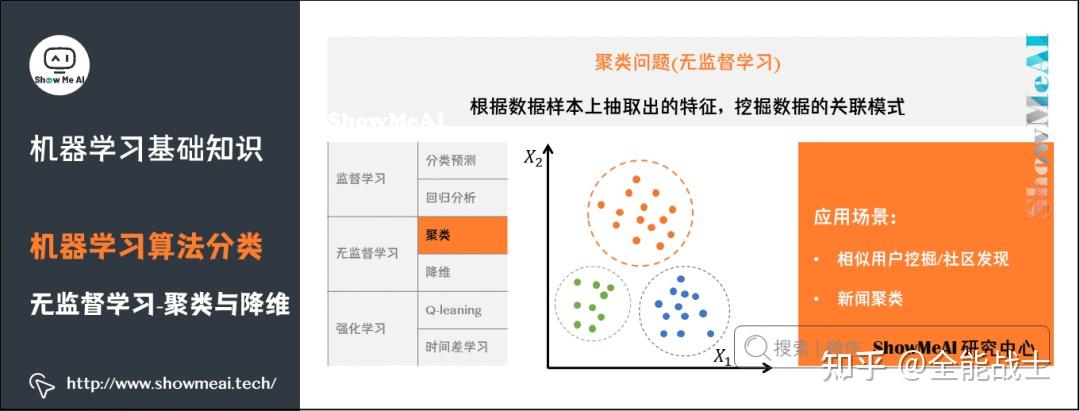
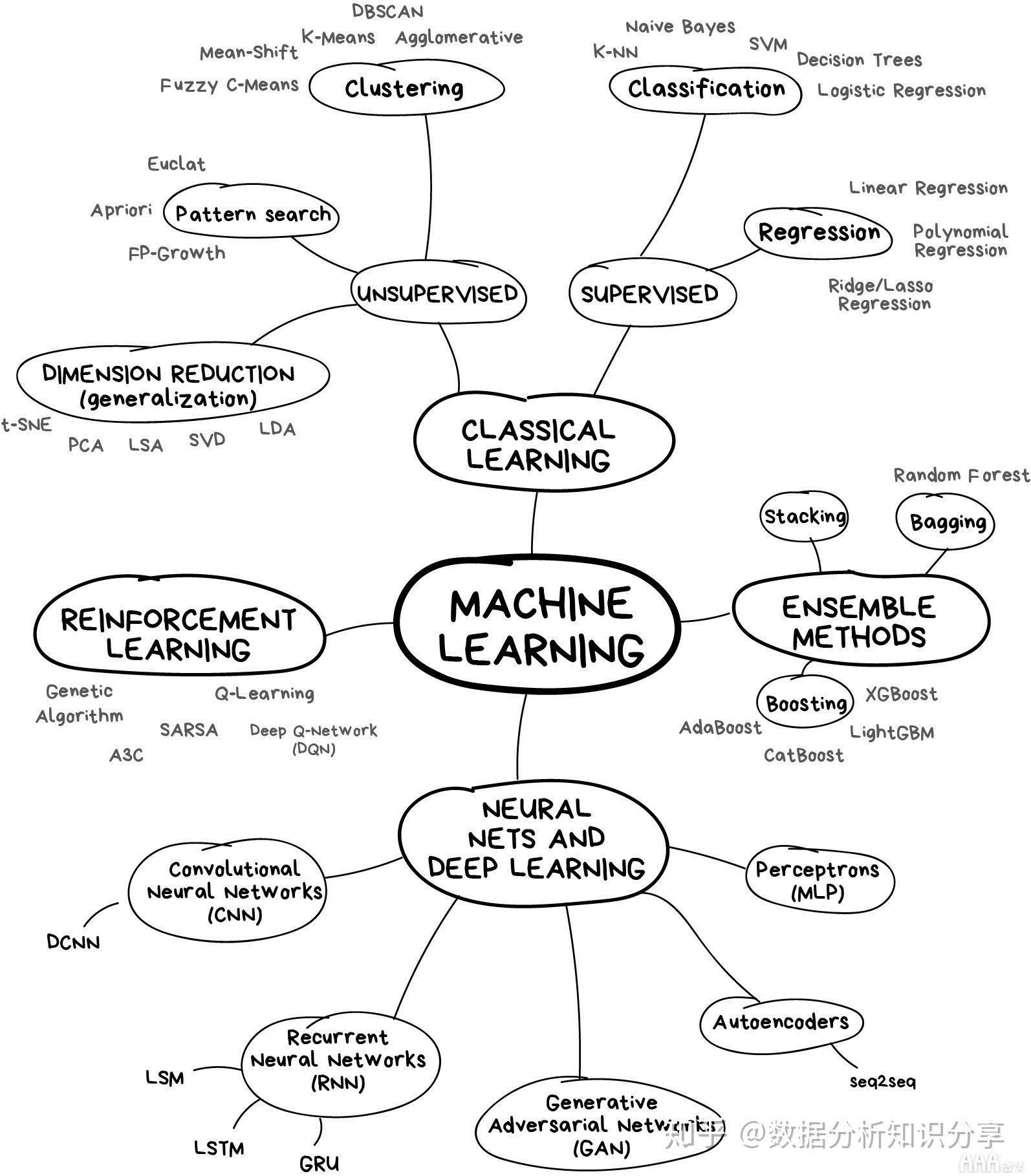
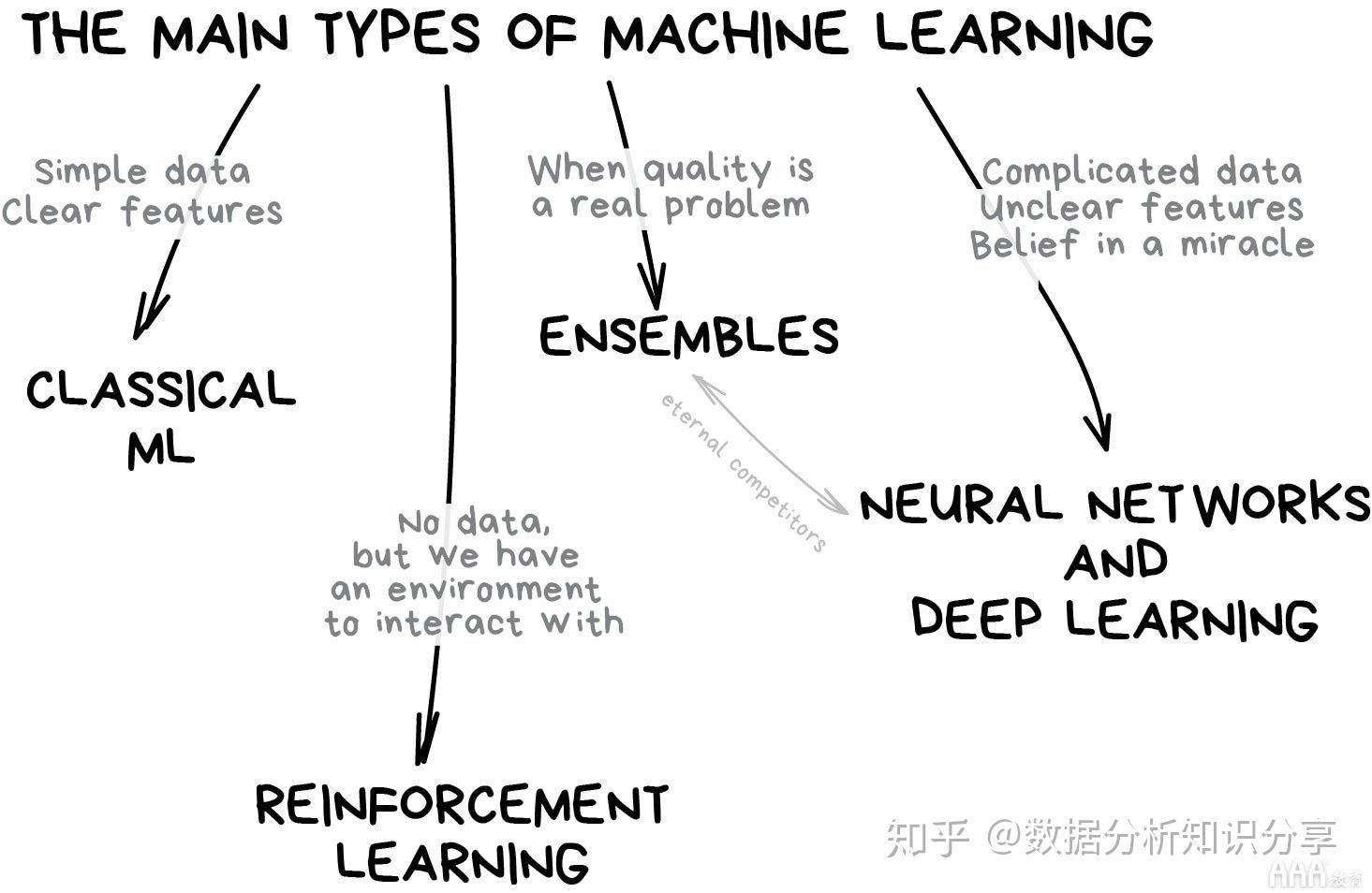
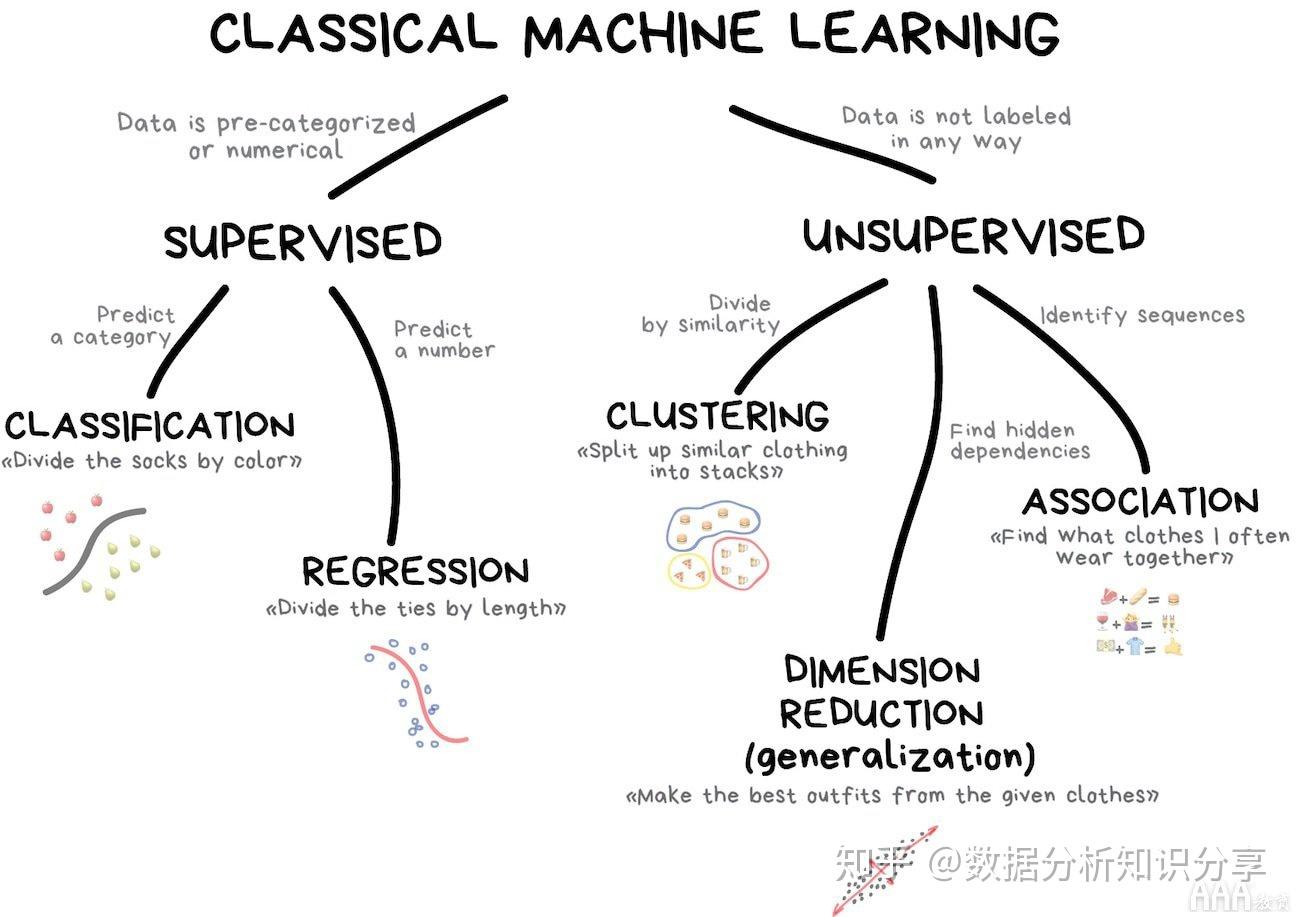
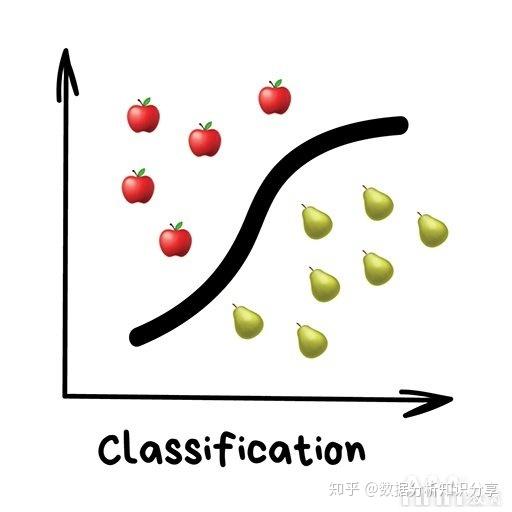
机器学习任务大致可以分为三类:监督学习、非监督学习和顺序学习。ML 中的数据可以是两种类型——有标记的和无标记的。

图 2 人工智能算法模型
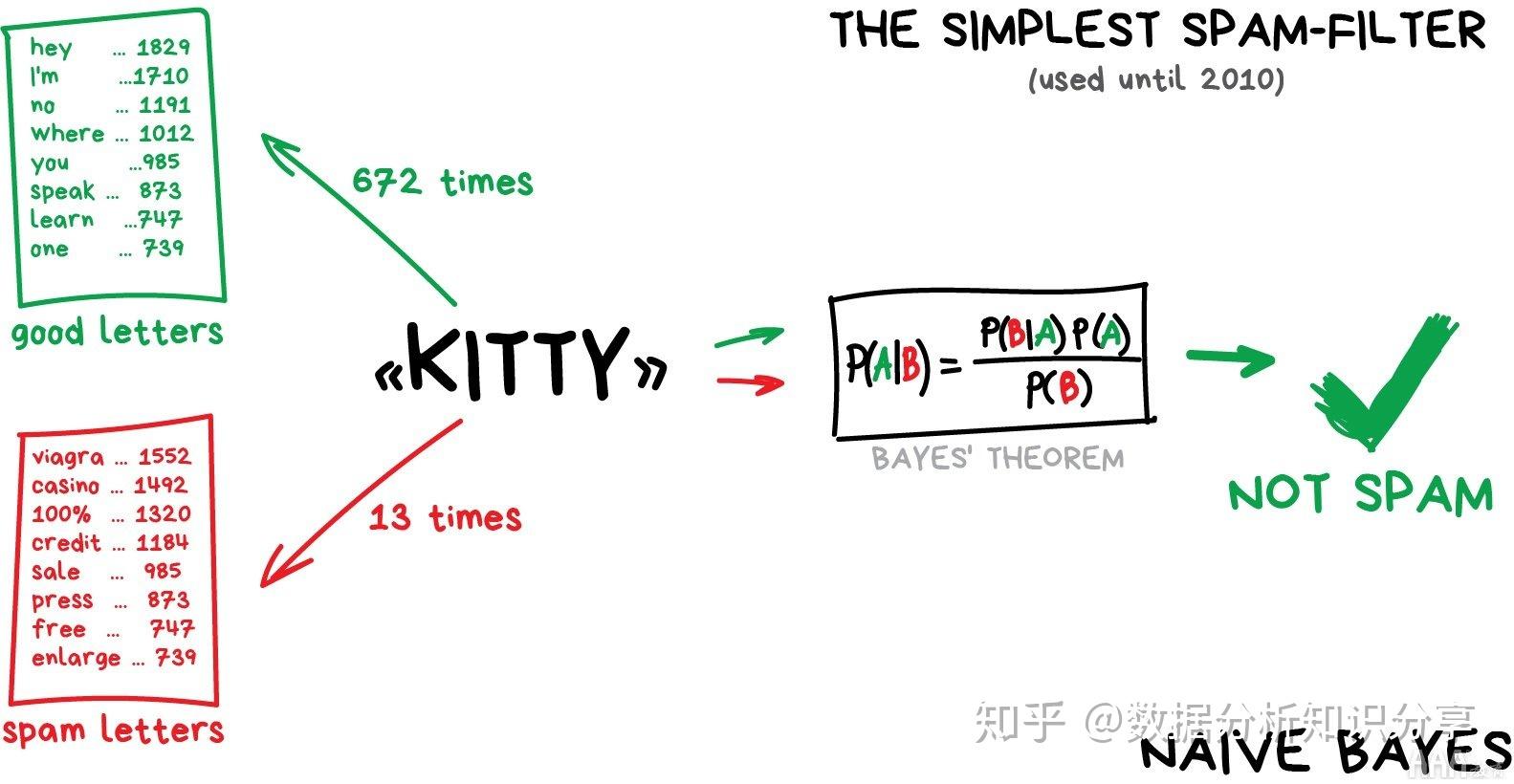
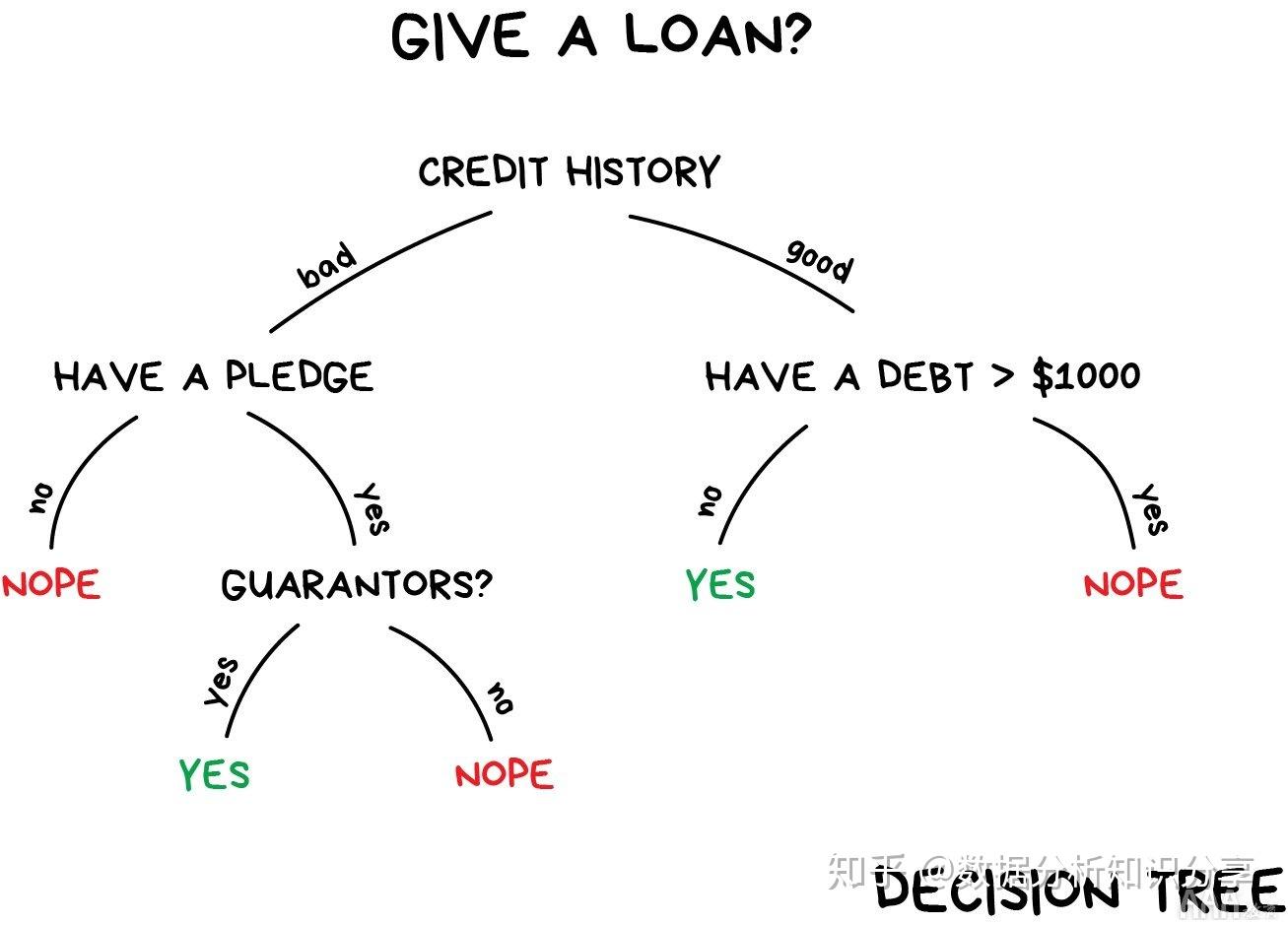
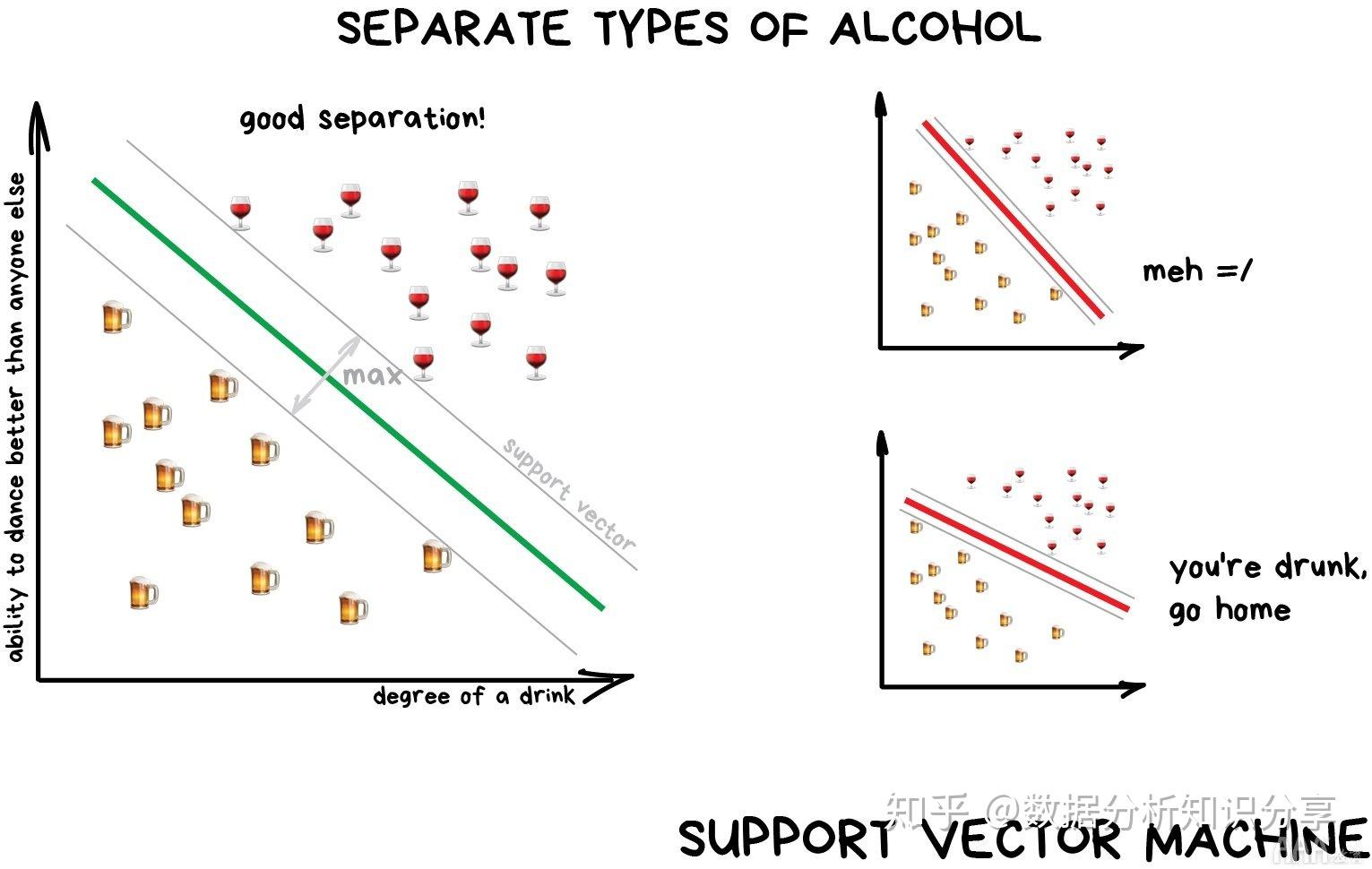
常见的机器学习算法包括决策树(decision tree)、 随机森林(random forest)、 支持向量机(support vector machine,SVM),k-最近邻算法(k-nearest neighbor model) 和朴素贝叶斯(Naïve Bayes)算法。
药物研发中,ML方法可应用于以下几个步骤:
- 药物靶点识别:工具-决策树
- 活性化合物筛选:工具-决策树、贝叶斯模型、k-最近邻算法
- 化合物性质预测:工具-决策树、贝叶斯模型等
- 分子生成:工具- RNN、CNN等
- 蛋白结构及蛋白配体相互作用预测:工具- DNN、CNN等
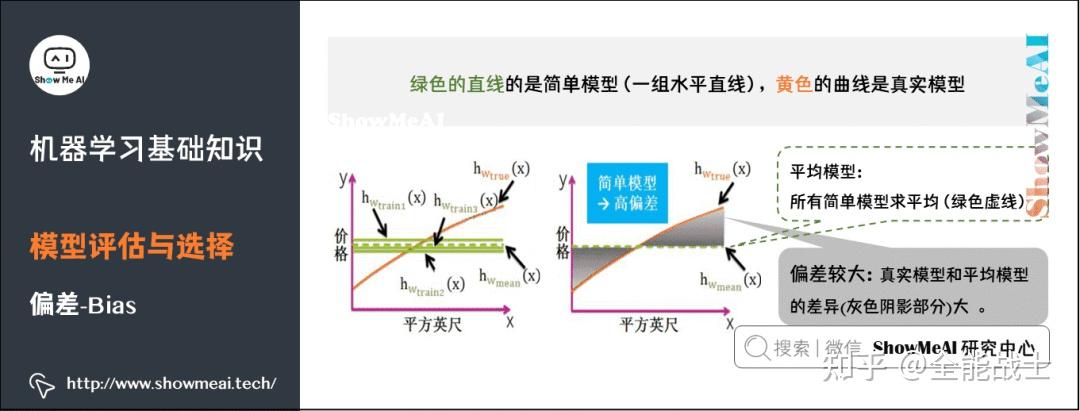
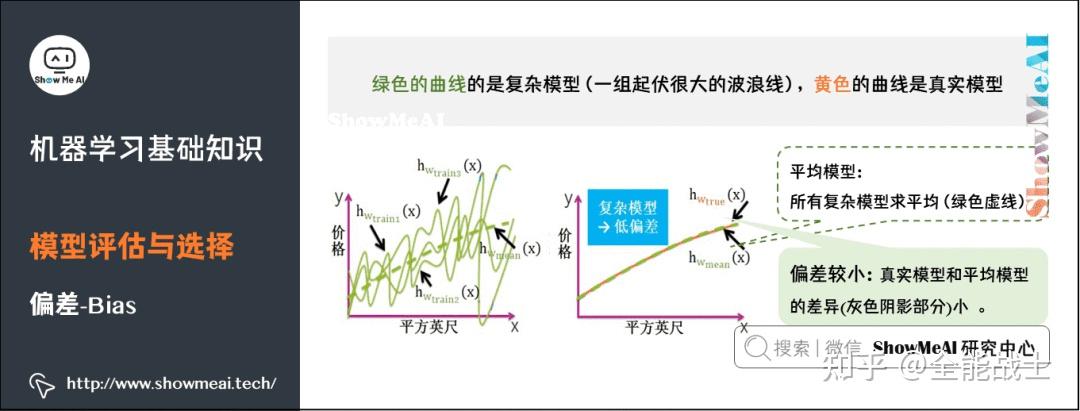
机器学习已被用于药物研发的各个领域,但是人工智能在新药研发中的应用才刚刚起步,也面临着诸多挑战。在药物研发领域,数据是人工智能的关键。因此作为一种数据挖掘技术,人工智能模型依赖于大数据的积累,并不能无中生有。用来学习的数据很大程度上会影响模型的性能,因此模型是否有效往往取决于数据的质量。若是数据质量不高,即使使用可靠的算法,也不会获得良好的结果,反而会浪费大量的资源和时间。目前大多数预测模型来源于参差不齐的数据,因此如何获得高质量的数据是人工智能面临的一个主要问题。此外,如何学习训练数据得到泛化能力强的模型也是人工智能的难点及热点。
参考资料:
- https://www.technologynetworks.com/drug-discovery/articles/automating-drug-discovery-with-machine-learning-347763
- Hong Ming Chen, et al. The rise of deep learning in drug discovery, Drug Discovery Today.
- Stephenson, Natalie,Survey of Machine Learning Techniques in Drug Discovery, Current Drug Metabolism.
- Vamathevan, Jessica Clark, Dominic Czodrowski, Paul Dunham, Ian Ferran, Edgardo Lee, George Li, Bin Madabhushi, Anant Shah, Parantu Spitzer, Michaela Zhao, Shanrong, Applications of machine learning in drug discovery and development, Nature Reviews Drug Discovery, 2019
- 参考书:图解机器学习
- https://blog.csdn.net/by4_Luminous/article/details/53341334
- 人工智能在药物发现中的应用与挑战
|